
Redis(十二)进阶:Redis分布式系统
Redis 分布式系统,官方称为 Redis Cluster,Redis 集群,其是 Redis 3.0 开始推出的分布式解决方案。其可以很好地解决不同 Redis 节点存放不同数据,并将用户请求方便地路由到不同 Redis 的问题。
数据分区算法
分布式数据库系统会根据不同的数据分区算法,将数据分散存储到不同的数据库服务器节点上,每个节点管理着整个数据集合中的一个子集。
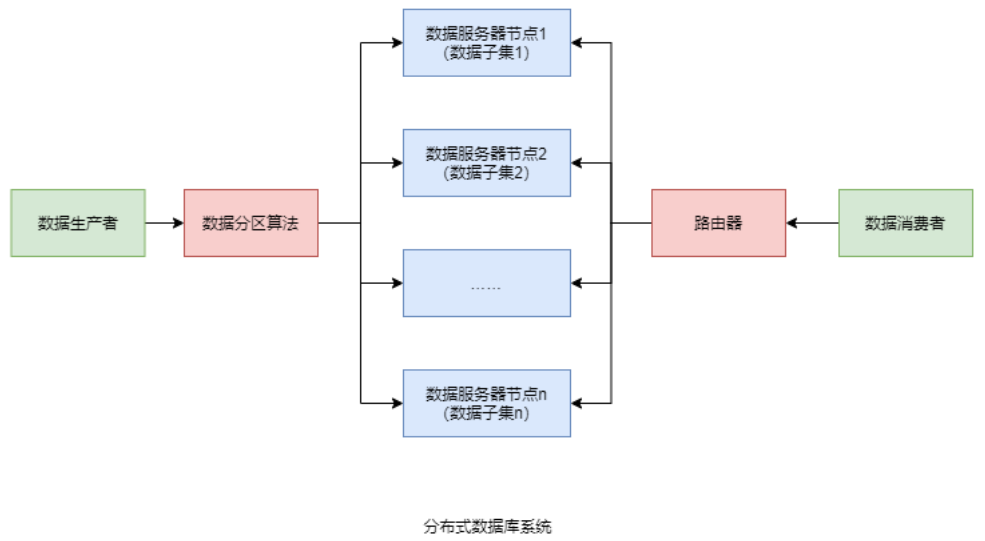
常见的数据分区规则有两大类:顺序分区与哈希分区。
顺序分区
顺序分区规则可以将数据按照某种顺序平均分配到不同的节点。不同的顺序方式,产生了不同的分区算法。例如,轮询分区算法、时间片轮转分区算法、数据块分区算法、业务主题分区算法等。由于这些算法都比较简单,所以这里就不展开描述了。
- 轮询分区算法
每产生一个数据,就依次分配到不同的节点。该算法适合于数据问题不确定的场景。其分配的结果是,在数据总量非常庞大的情况下,每个节点中数据是很平均的。但生产者与数据节点间的连接要长时间保持。
- 时间片轮转分区算法
在某人固定长度的时间片内的数据都会分配到一个节点。时间片结束,再产生的数据就会被分配到下一个节点。这些节点会被依次轮转分配数据。该算法可能会出现节点数据不平均的情况(因为每个时间片内产生的数据量可能是不同的)。但生产者与节点间的连接只需占用当前正在使用的这个就可以,其它连接使用完毕后就立即释放。
- 数据块分区算法
在整体数据总量确定的情况下,根据各个节点的存储能力,可以将连接的某一整块数据分配到某一节点。
- 业务主题分区算法
数据可根据不同的业务主题,分配到不同的节点。
哈希分区
哈希分区规则是充分利用数据的哈希值来完成分配,对数据哈希值的不同使用方式产生了不同的哈希分区算法。哈希分区算法相对较复杂,这里详细介绍几种常见的哈希分区算法。
- 节点取模分区算法
该算法的前提是,每个节点都已分配好了一个唯一序号,对于 N 个节点的分布式系统,其序号范围为[0, N-1]。然后选取数据本身或可以代表数据特征的数据的一部分作为 key,计算 hash(key)与节点数量 N 的模,该计算结果即为该数据的存储节点的序号。
该算法最大的优点是简单,但其也存在较严重的不足。如果分布式系统扩容或缩容,已经存储过的数据需要根据新的节点数量 N 进行数据迁移,否则用户根据 key 是无法再找到原来的数据的。生产中扩容一般采用翻倍扩容方式,以减少扩容时数据迁移的比例。
- 一致性哈希分区算法
一致性 hash 算法通过一个叫作一致性 hash 环的数据结构实现。这个环的起点是 0,终点是 2^32 - 1,并且起点与终点重合。环中间的整数按逆/顺时针分布,故这个环的整数分布范围是[0, 2^32-1]。
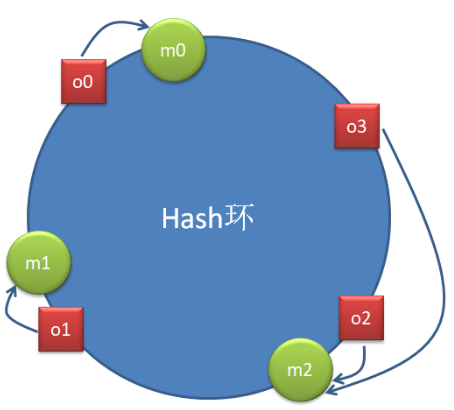
上图中存在四个对象 o1、o2、o3、o4,分别代表四个待分配的数据,红色方块是这四个数据的 hash(o)在 Hash 环中的落点。同时,图上还存在三个节点 m0、m1、m2,绿色圆圈是这三节点的 hash(m)在 Hash 环中的落点。
现在要为数据分配其要存储的节点。该数据对象的 hash(o) 按照逆/顺时针方向距离哪个节点的 hash(m)最近,就将该数据存储在哪个节点。这样就会形成上图所示的分配结果。
该算法的最大优点是,节点的扩容与缩容,仅对按照逆/顺时针方向距离该节点最近的节点有影响,对其它节点无影响。
当节点数量较少时,非常容易形成数据倾斜问题,且节点变化影响的节点数量占比较大,即影响的数据量较大。所以,该方式不适合数据节点较少的场景。
- 虚拟槽分区算法
该算法首先虚拟出一个固定数量的整数集合,该集合中的每个整数称为一个 slot 槽。这个槽的数量一般是远远大于节点数量的。然后再将所有 slot 槽平均映射到各个节点之上。例如,Redis 分布式系统中共虚拟了 16384 个 slot 槽,其范围为[0, 16383]。假设共有 3 个节点,那么 slot 槽与节点间的映射关系如下图所示:
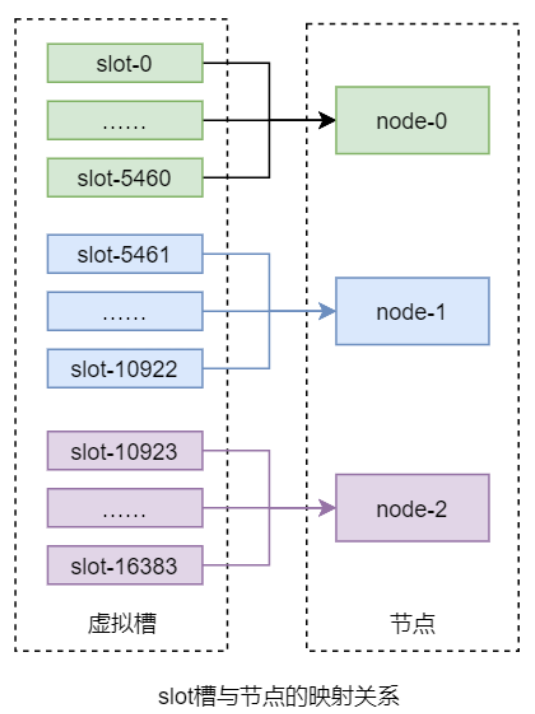
而数据只与 slot 槽有关系,与节点没有直接关系。数据只通过其 key 的 hash(key)映射到slot 槽:slot = hash(key) % slotNums。这也是该算法的一个优点,解耦了数据与节点,客户端无需维护节点,只需维护与 slot 槽的关系即可。
Redis 数据分区采用的就是该算法。其计算槽点的公式为:slot = CRC16(key) % 16384。CRC16()是一种带有校验功能的、具有良好分散功能的、特殊的 hash 算法函数。其实 Redis中计算槽点的公式不是上面的那个,而是:slot = CRC16(key) &16383。
若要计算 a % b,如果 b 是 2 的整数次幂,那么 a % b = a & (b-1)。
系统搭建与运行
系统搭建
- 系统架构
下面要搭建的 Redis 分布式系统由 6 个节点构成,这 6 个节点的地址及角色分别如下表所示。一个 master 配备一个 slave,不过 master 与 slave 的配对关系,在系统搭建成功后会自动分配。
| 序号 | 角色 | 地址 |
|---|---|---|
| 1 | master | 127.0.0.1:6380 |
| 2 | master | 127.0.0.1:6381 |
| 3 | master | 127.0.0.1:6382 |
| 4 | slave | 127.0.0.1:6383 |
| 5 | slave | 127.0.0.1:6384 |
| 6 | slave | 127.0.0.1:6385 |
- 删除持久化文件
Redis 分布式系统要求创建在一个空的数据库之上,AOF持久化文件全部在 appendonlydir 目录中。
- 创建目录
在 Redis 安装目录中 mkdir 一个新的目录 cluster-dis,用作分布式系统的工作目录。
- 编写配置文件
公共配置文件redis.conf
cluster-enabled

该属性用于开启 Redis 的集群模式。
cluster-config-file

该属性用于指定“集群节点”的配置文件。该文件会在第一次节点启动时自动生成,其生成的路径是在 dir 属性指定的工作目录中。在集群节点信息发生变化后(如节点下线、故障转移等),节点会自动将集群状态信息保存到该配置文件中。
不过,该属性在这里仍保持注释状态。在后面的每个节点单独的配置文件中配置它。
cluster-node-timeout

用于指定“集群节点”间通信的超时时间阈值,单位毫秒。
各个结点配置文件
redis6380.conf:
1 | include redis.conf |
其他6381~6385只需修改端口相关参数即可。
一共7个配置文件

系统启动与关闭
- 启动节点
通过redis-server redis6380.conf &启动所有redis
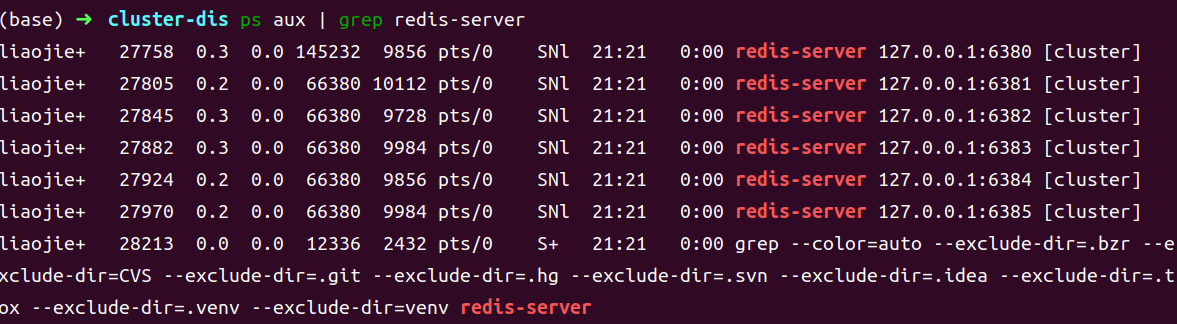
此时查看 cluster-dis 目录,可以看到生成了 6 个 nodes 的配置文件。

- 创建系统
6 个节点启动后,它们仍是 6 个独立的 Redis,通过 redis-cli --cluster create 命令可将 6个节点创建了一个分布式系统。
1 | redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 # 最好是使用自己ip,这里只是演示 |
该命令用于将指定的 6 个节点连接为一个分布式系统。–cluster replicas 1 指定每个master 会带有一个 slave 作为副本。
回车后会立即看到如下日志:
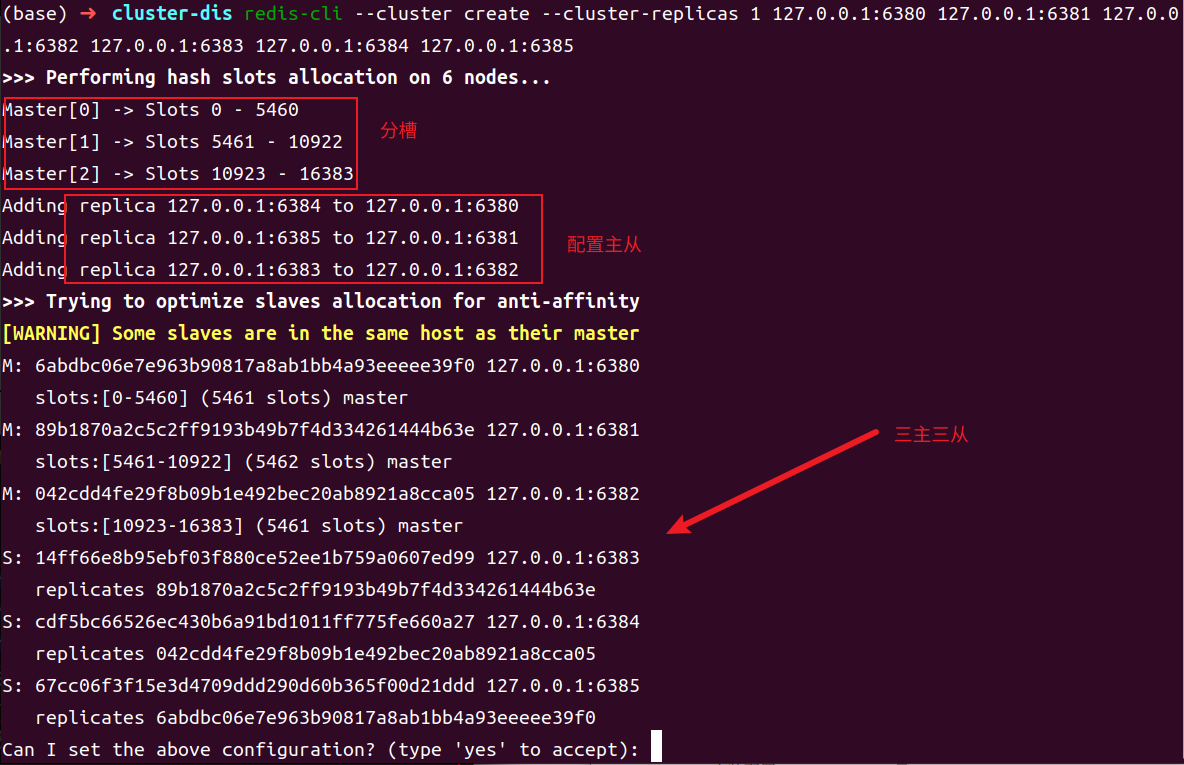
输入 yes 后回车,系统就会将以上显示的动态配置信息真正的应用到节点上,然后就可可看到如下日志:
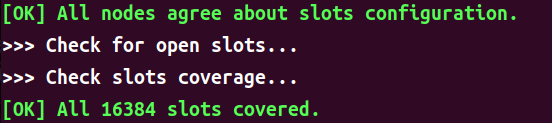
- 测试系统
1 | redis-cli -c -p 6380 cluster nodes |
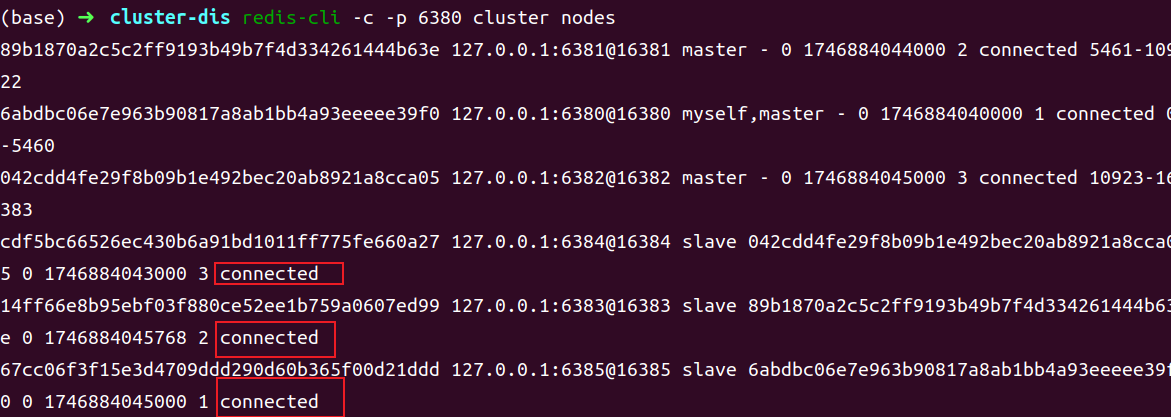
通过 cluster nodes 命令可以查看到系统中各节点的关系及连接情况。只要能看到每个节点给出 connected,就说明分布式系统已经成功搭建。不过,对于客户端连接命令 redis-cli,需要注意两点:
redis-cli 带有-c 参数,表示这是要连接一个“集群”,而非是一个节点。
端口号可以使用 6 个中的任意一个。
- 关闭系统
对于分布式系统的关闭,只需将各个节点 shutdown 即可。
redis-cli -p 6380 shutdown
- 快速启动脚本
只限本机使用,生产环境下ip不同还是老老实实手动吧。
start.sh
1 |
|
shutdown.sh
1 |
|
可执行权限chmod +x start.sh
集群操作
连接集群
1 | redis-cli -c -p 6380 # 端口随便哪个都行 |
与之前单机连接相比的唯一区别就是增加了参数-c。
写入数据
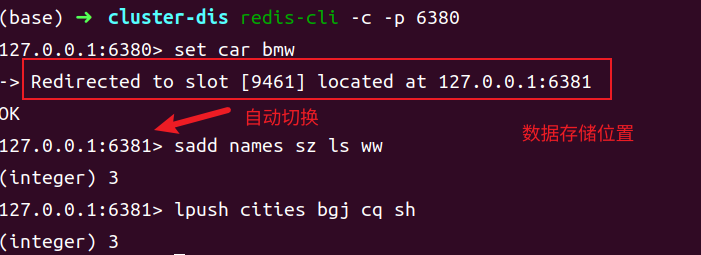
- key 单个写入
无论 value 类型为 String 还是 List、Set 等集合类型,只要写入时操作的是一个 key,那么在分布式系统中就没有问题。例如
- key 批量操作
对一次写入多个 key 的操作,由于多个 key 会计算出多个 slot,多个 slot 可能会对应多个节点。而由于一次只能写入一个节点,所以该操作会报错。

不过,系统也提供了一种对批量 key 的操作方案,为这些 key 指定一个统一的 group,让这个 group 作为计算 slot 的唯一值。mset name{emp} zs age{emp} 23 depart{emp} market

集群查询
- 查询 key 的 slot
通过 cluster keyslot 可以查询指定 key 的 slot。例如,下面是查询 emp 的 slot。cluster keyslot emp

- 查询 slot 中 key 的数量
通过 cluster countkeysinslot命令可以查看到指定 slot 所包含的 key 的个数。

- 查询 slot 中的 key
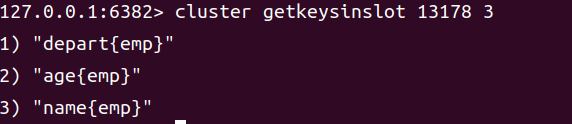
通过 cluster getkeysinslot 命令可以查看到指定 slot 所包含的 key。
故障转移
分布式系统中的某个 master 如果出现宕机,那么其相应的 slave 就会自动晋升为 master。如果原 master 又重新启动了,那么原 master 会自动变为新 master 的 slave。
- 模拟故障
通过 cluster nodes 命令可以查看系统的整体架构及连接情况。

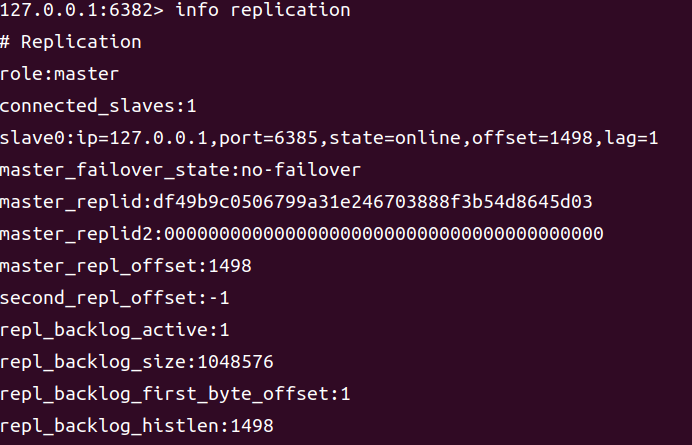
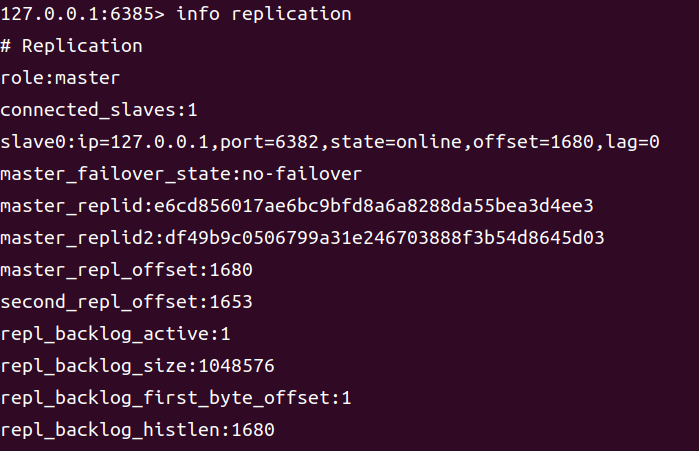
当然,也可以通过 info replication 查看当前客户端连接的节点的角色。可以看到,6382节点是 master,其 slave 为 6385节点。
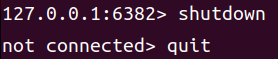
为了模拟 6382宕机,直接将其 shutdown。
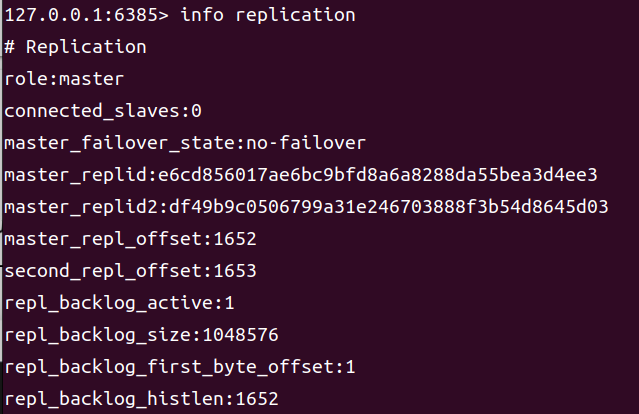
通过客户端连接上 6385 节点后可以查看到,其已经自动晋升为了 master。
重启 6382 节点后查看其角色,发现其自动成为了 6385 节点的 slave。
- 全覆盖需求
如果某 slot 范围对应节点的 master 与 slave 全部宕机,那么整个分布式系统是否还可以对外提供读服务,就取决于属性 cluster-require-full-coverage 的设置。
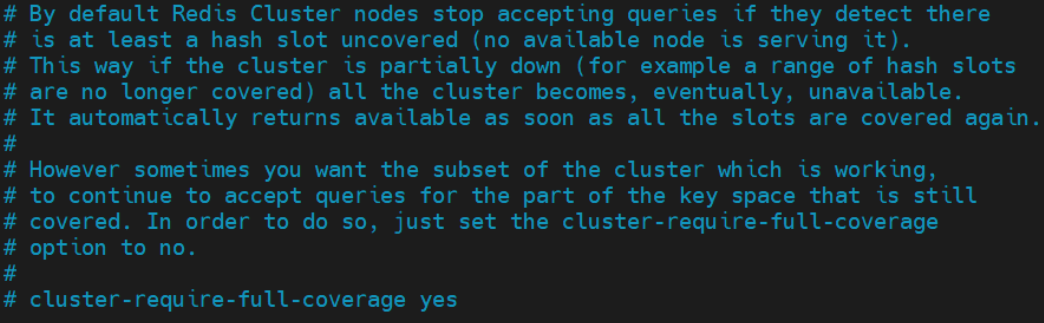
该属性有两种取值:
- yes:默认值。要求所有 slot 节点必须全覆盖的情况下系统才能运行。
- no:slot 节点不全的情况下系统也可以提供查询服务。
集群扩容
下面要在正在运行的分布式系统中添加两个新的节点:端口号为 6386 的节点为 master节点,其下会有一个端口号为 6387 的 slave 节点。
使用 redis6380.conf 复制出 2 个配置文件 redis6386.conf 与 redis6387.conf,并修改其中的各处端口号为相应端口号,为集群扩容做前期准备。要添加的两个节点是两个 Redis,所以需要先将它们启动。只不过,在没有添加到分布式系统之前,它们两个是孤立节点,每个节点与其它任何节点都没有关系。
- 添加 master 节点
1 | redis-cli -c --cluster add-node 127.0.0.1:6386 127.0.0.1:6380 # 集群中任意一个端口都行,不一定是6380 |
通过命令 redis-cli --cluster add-node {newHost}:{newPort} {existHost}:{existPort}可以将新的节点添加到系统中。其中{newHost}:{newPort}是新添加节点的地址,{existHost}:{existPort}是原系统中的任意节点地址。
添加成功后可看到如下日志。
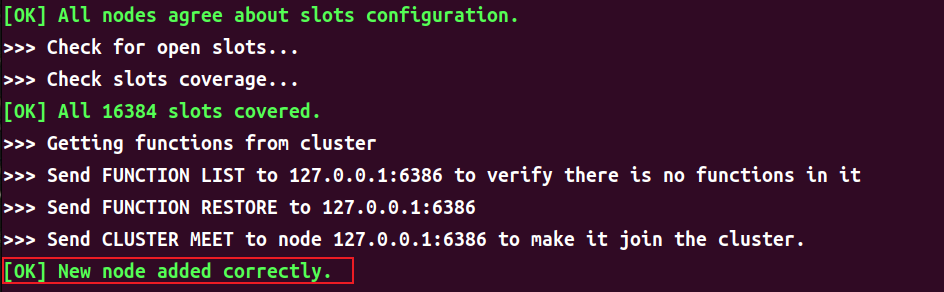
添加成功后,通过 redis-cli -c -p 6386 cluster nodes 命令可以看到其它 master 节点都分配有 slot,只有新添加的 master 还没有相应的 slot。当然,通过该命令也可以看到该新节点的动态 ID。

- 分配 slot
为新的 master 分配的 slot 来自于其它节点,总 slot 数量并不会改变。所以 slot 分配过程本质是一个 slot 的移动过程。
通过 redis-cli –c --cluster reshard {existIP}:{existPort}命令可开启 slot 分配流程。其中地址{existIP}:{existPort}为分布式系统中的任意节点地址。
1 | redis-cli -c --cluster reshard 127.0.0.1:6381 |
该流程中会首先查询出当前节点的 slot 分配情况:
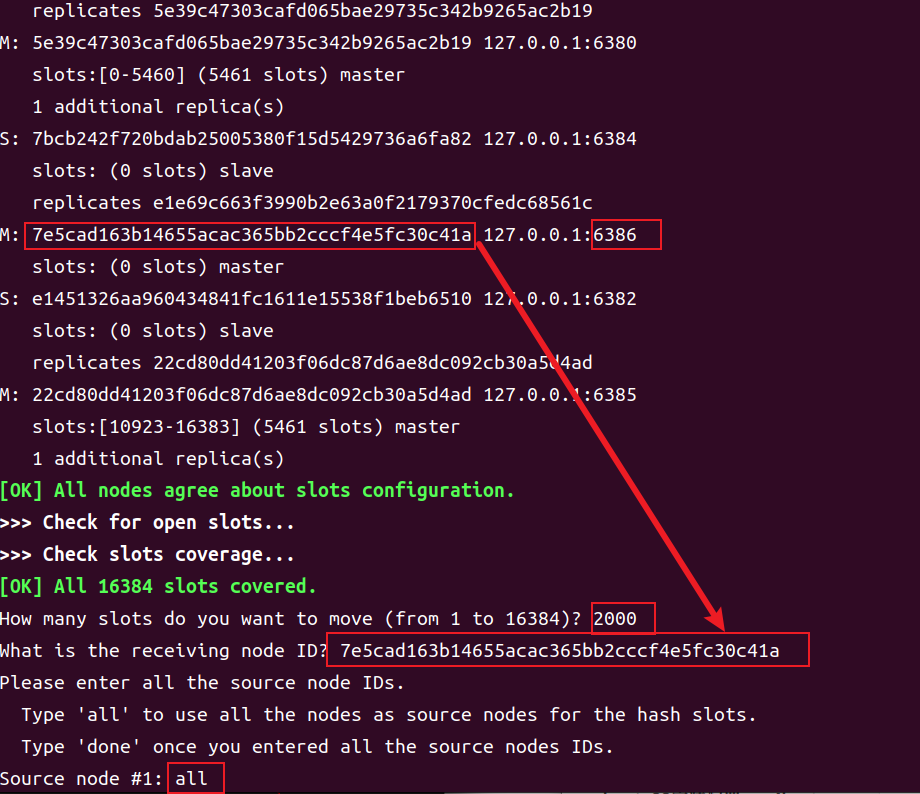
然后开始 Q&A 交互。一共询问了四个问题,这里有三个:
- 准备移动多少 slot?
- 准备由谁来接收移动的 slot?
- 选择要移动 slot 的源节点。有两种方案。如果选择键入 all,则所有已存在 slot 的节点都将作为 slot 源节点,即该方案将进行一次 slot 全局大分配。也可以选择其它部分节点作为 slot 源节点。此时将源节点的动态 ID 复制到这里,每个 ID 键入完毕后回车,然后再复制下一个 slot 源节点动态 ID,直至最后一个键入完毕回车后再键入 done。
这里键入的是 all,进行全局大分配。
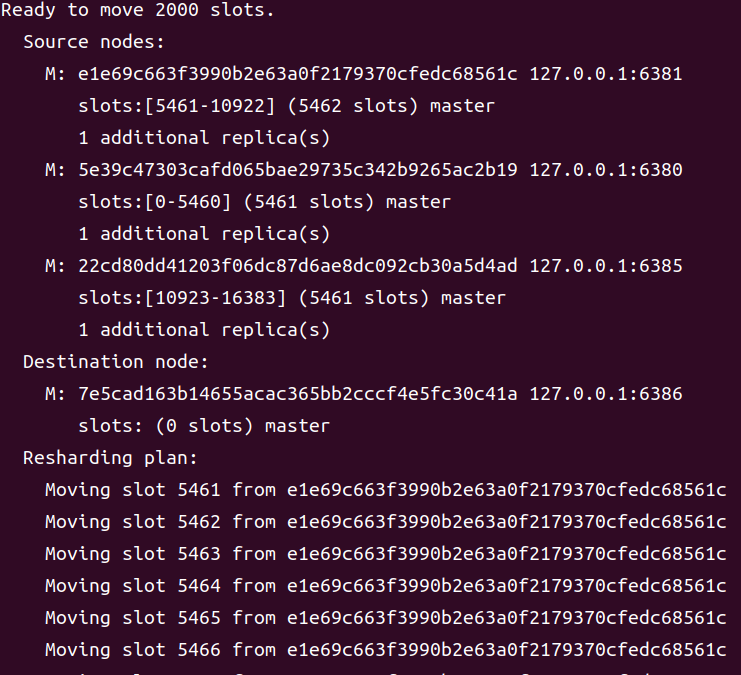
其首先会检测指定的 slot 源节点的数据,然后制定出 reshard 的方案。
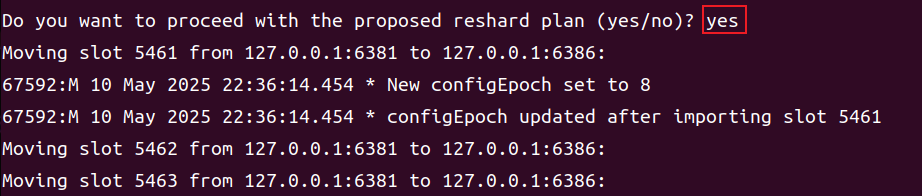
这里会再进行一次 Q&A 交互,询问是否想继续处理推荐的方案。键入 yes,然后开始真正的全局分配,直至完成。
此时再通过 redis-cli -c -p 6386 cluster nodes 命令查看节点信息,可以看到 6386 节点中已经分配了 slot,只不过分配的 slot 编号并不连续。master 节点新增完成。

- 添加 slave 节点
现要将 6387 节点添加为 6386 节点的 slave。当然,首先要确保 6387 节点的 Redis 是启动状态。
通过 redis-cli --cluster add-node {newHost}:{newPort} {existHost}:{existPort} --cluster-slave --cluster-master-id masterID 命令可将新添加的节点直接添加为指定 master 的 slave。
1 | redis-cli --cluster add-node 127.0.0.1:6387 127.0.0.1:6380 --cluster-slave --cluster-master-id 7e5cad163b14655acac365bb2cccf4e5fc30c41a |
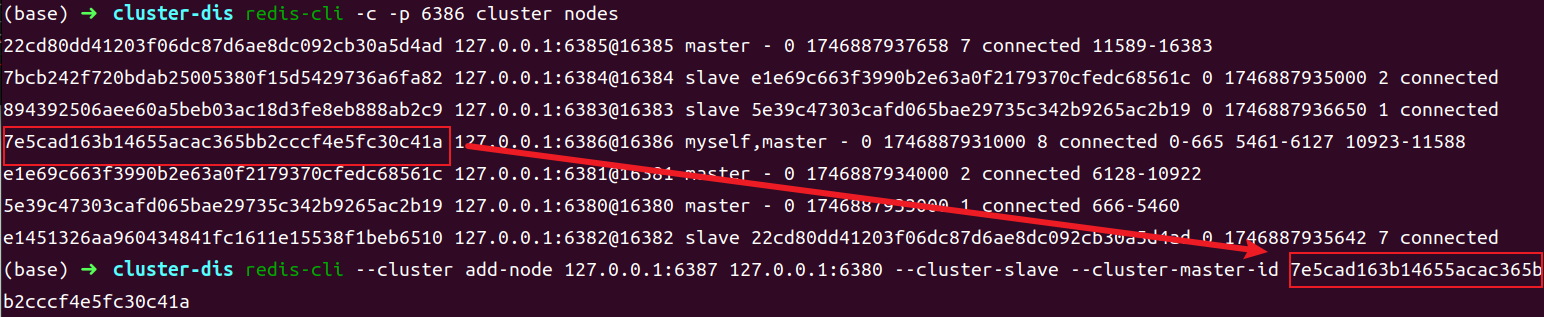
回车后可看到如下的日志,说明添加成功。
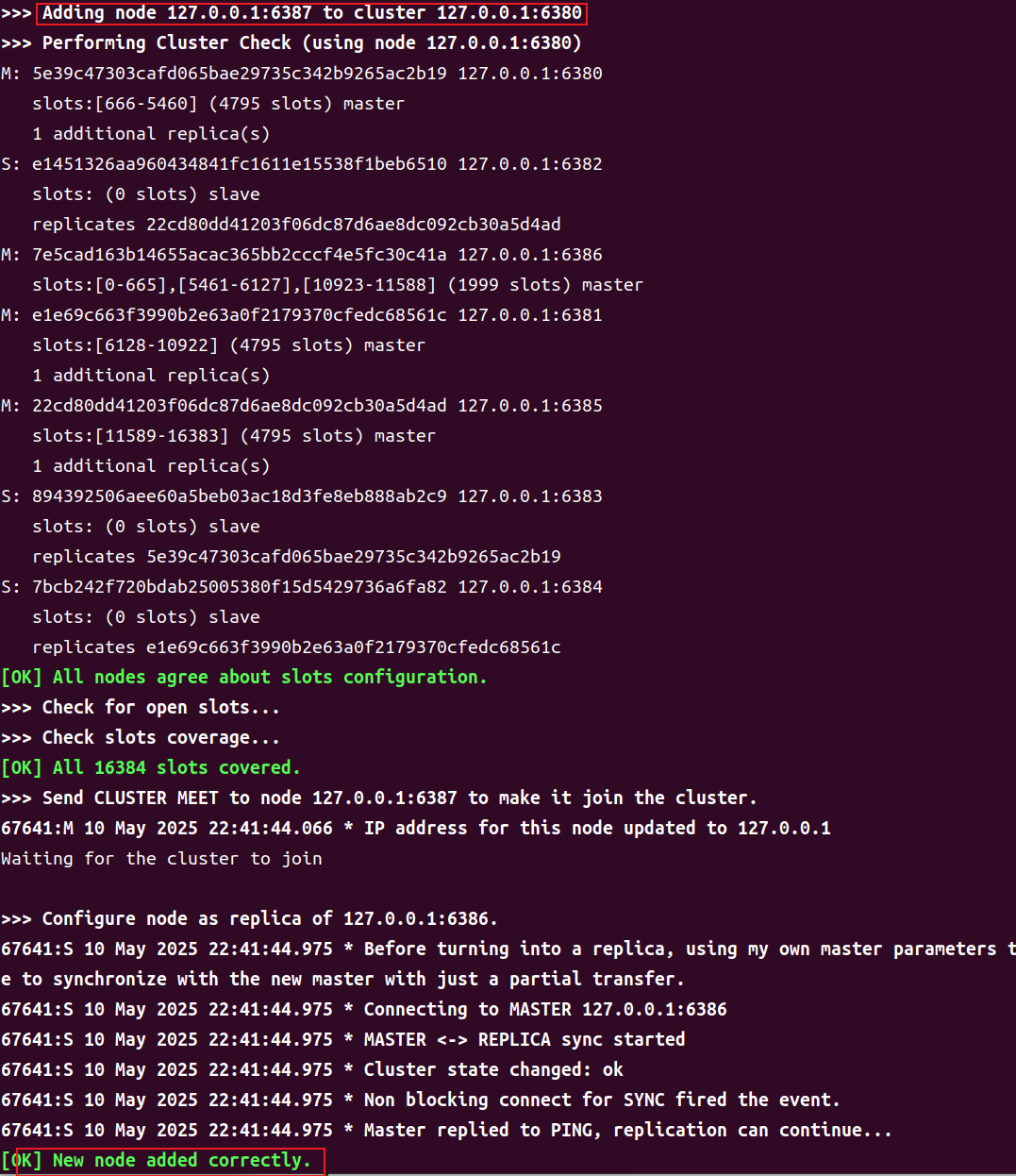
此时再通过 redis-cli -c -p 6386 cluster nodes 命令可以看到其已经添加成功,且为指定master 的 slave。

集群缩容
下面要将 slave 节点 6387 与 master 节点 6386 从分布式系统中删除。
- 删除 slave 节点
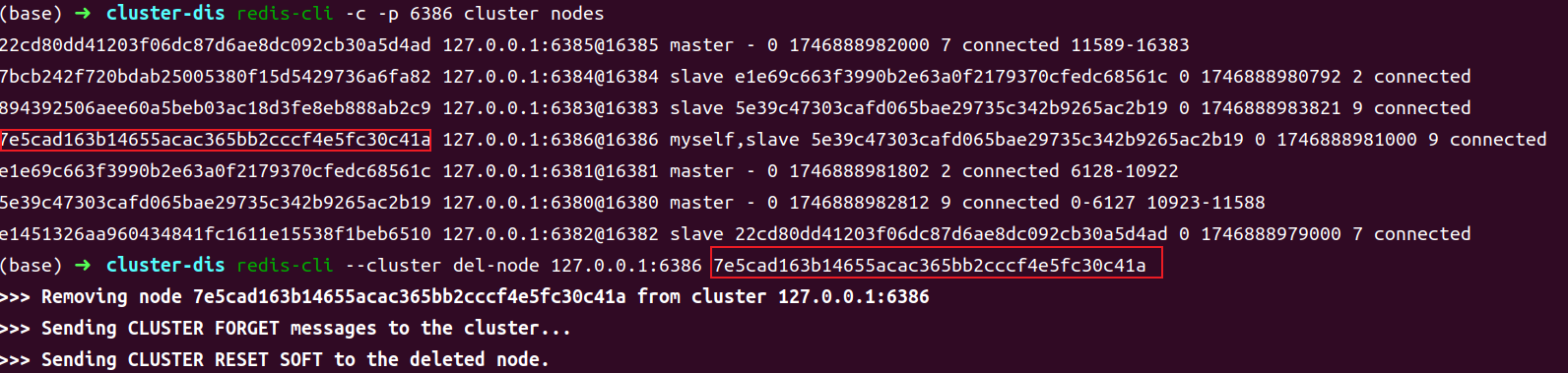
对于 slave 节点,可以直接通过 redis-cli --cluster del-node <delHost>:<delPort> delNodeID命令删除。


- 移出 master 的 slot
在删除一个 master 之前,必须要保证该 master 上没有分配有 slot。否则无法删除。所以,在删除一个 master 之前,需要先将其上分配的 slot 移出。
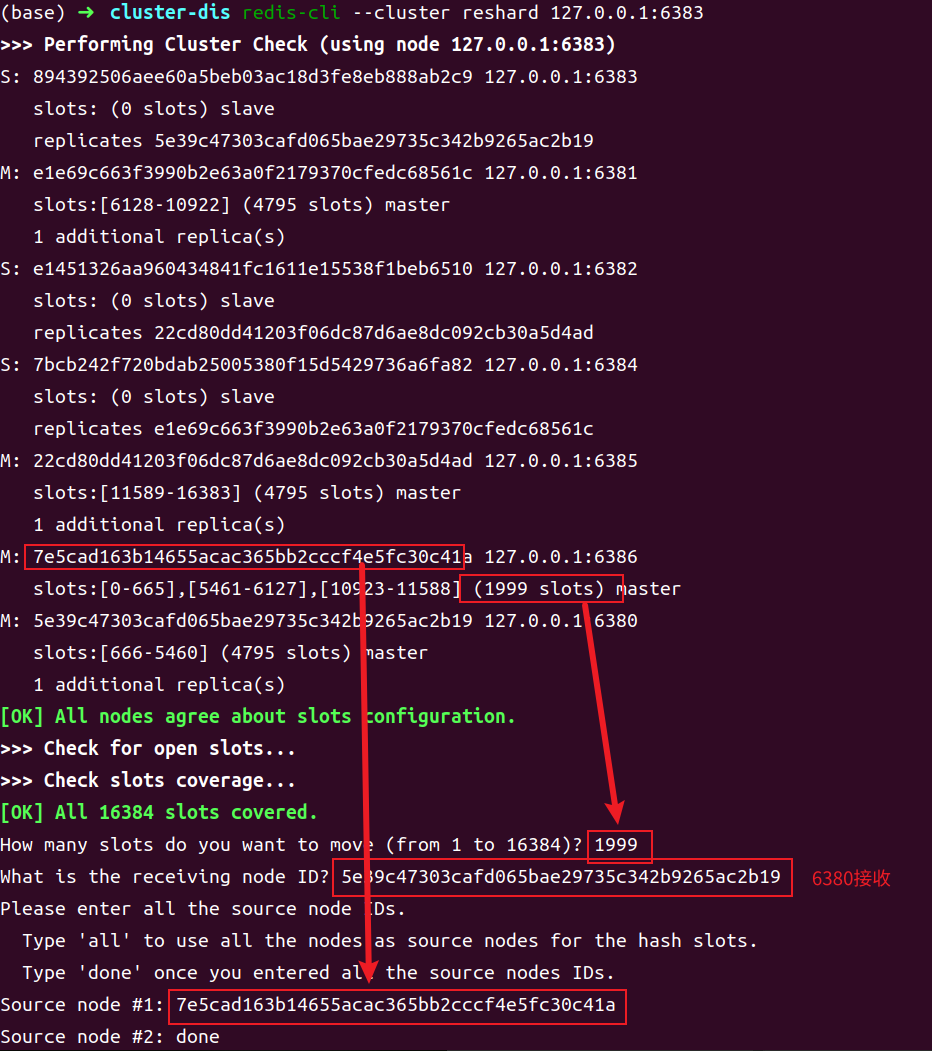
以上交互指定的是将 6386 节点中的 1999 个 slot 移动到 6380 节点。
注意:
- 要删除的节点所包含的 slot 数量在前面检测结果中都是可以看到的,例如,6386 中的并不是 2000 个,而是 1999 个
- What is the receiving node ID?仅能指定一个接收节点
回车后继续yes即可。
此时再查看发现,6386 节点中已经没有 slot 了。

- 删除 master 节点
按照1删除 slave 节点删除 6386 节点就行了。
1 | redis-cli --cluster del-node 127.0.0.1:6386 7e5cad163b14655acac365bb2cccf4e5fc30c41a |

分布式系统的限制
Redis 的分布式系统存在一些使用限制:
- 仅支持 0 号数据库
- 批量 key 操作支持有限
- 分区仅限于 key
- 事务支持有限
- 不支持分级管理









