
Redis(十一)进阶:Redis缓存穿透、击穿和雪崩的理解和学习
Redis的缓存穿透
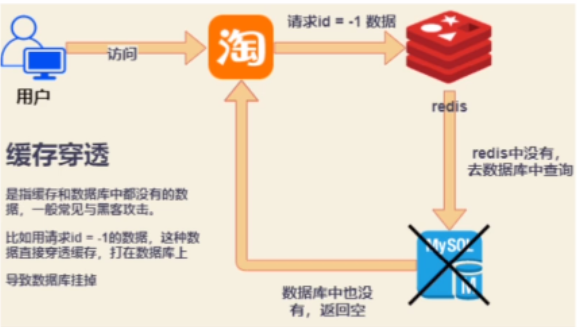
1、概念:
用户需要查询一个数据,但是redis中没有(比如说mysql中id=-1的数),直接去请求MySQL,当很多用户同时请求并且都么有命中!于是都去请求了持久层的数据库,那么这样会给持久层数据库带来非常大的压力。一般出现这样的情况都不是正常用户,基本上都是恶意用户!
2、解决方案
①布隆过滤器:
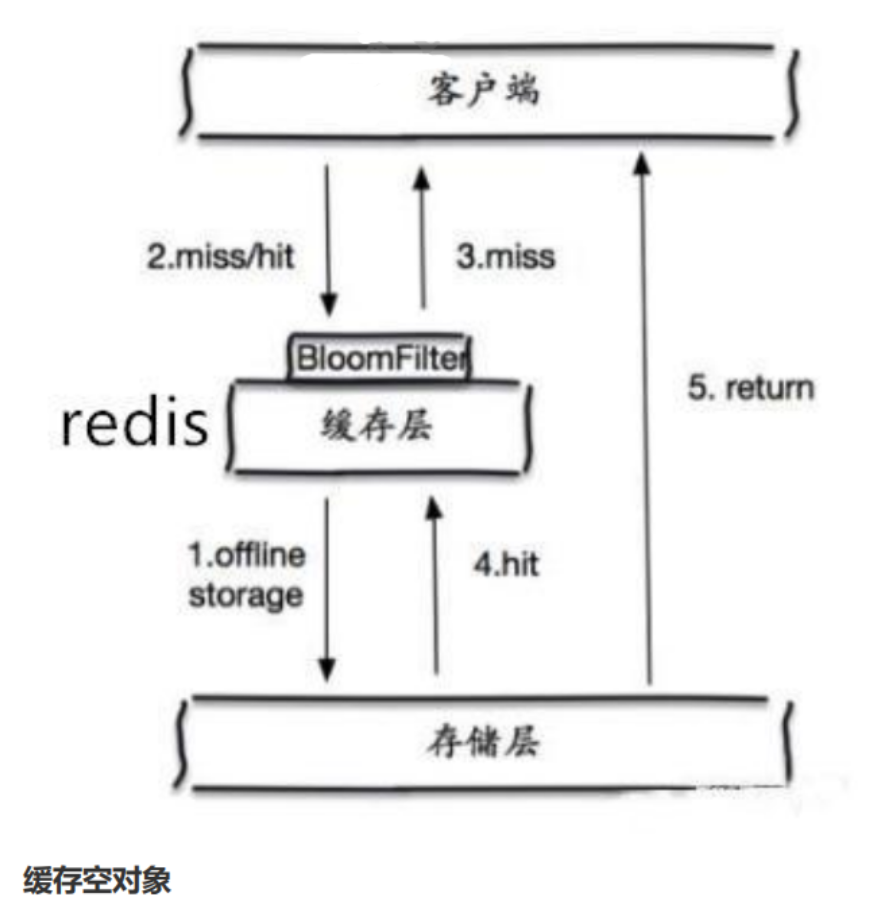
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则
丢弃,从而避免了对底层存储系统的查询压力;
②缓存空对象:
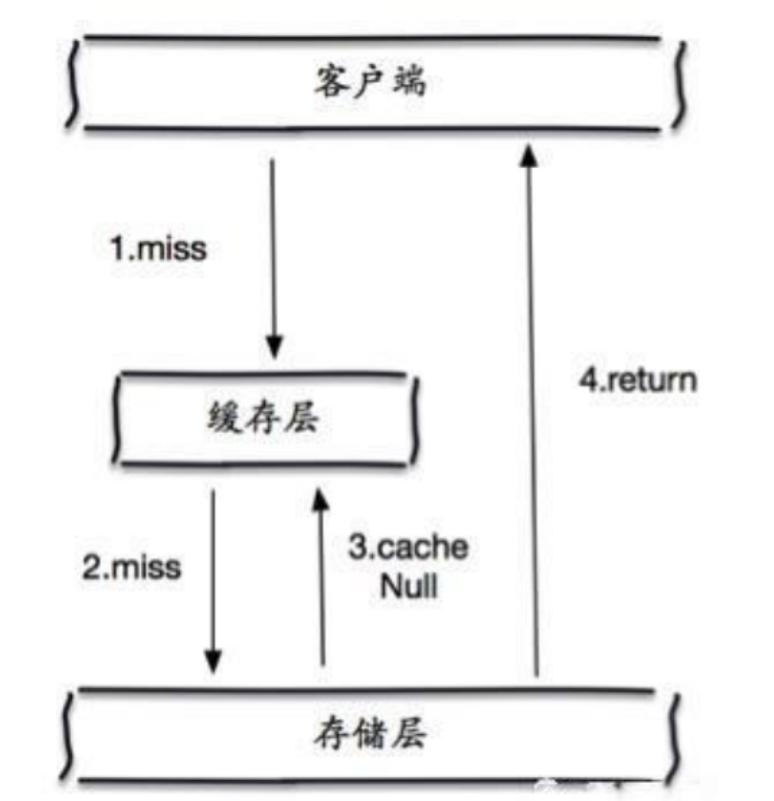
当存储层查不到,即使是空值,我们也将其存储起来并且在Redis中设置一个过期时间,之后再访问这个数据将会从Redis中访问,保护了持久层的数据库!
③存在的问题:
1)如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
2)即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
注意:缓存穿透前提是:Redis和MySQL中都没有,然后不停的直接请求MySQL。
Redis的缓存击穿
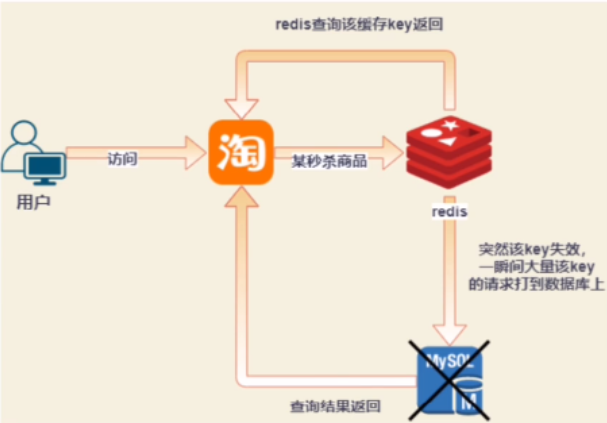
1、概念:
是指一个非常热点的key,在不停的扛着大并发,当这个key失效时,一瞬间大量的请求冲到持久层的数据库中,就像在一堵墙上某个点凿开了一个洞!
2、解决方案:
①设置热点key永不过期:
从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题。
②加互斥锁:
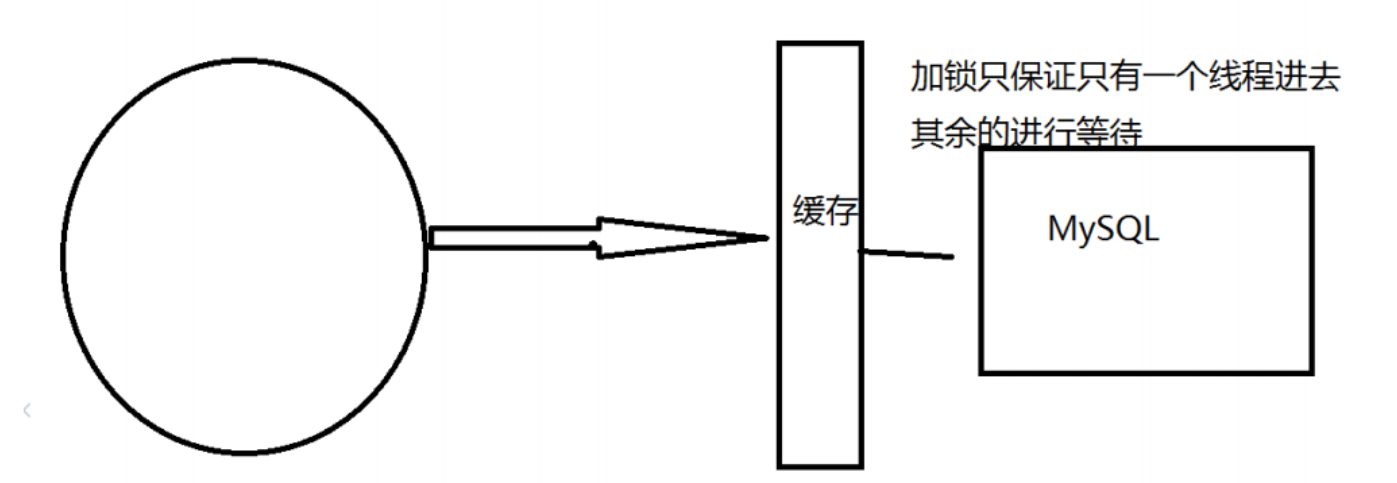
在查询持久层数据库时,保证了只有一个线程能够进行持久层数据查询,其他的线程让它睡眠几百毫秒,等待第一个线程查询完会回写到Redis缓存当中,剩下的线程可以正常查询Redis缓存,就不存在大量请求去冲击持久层数据库了!
③双重检测锁
④缺点:
其实设置永不过期不合理!
Redis的缓存雪崩
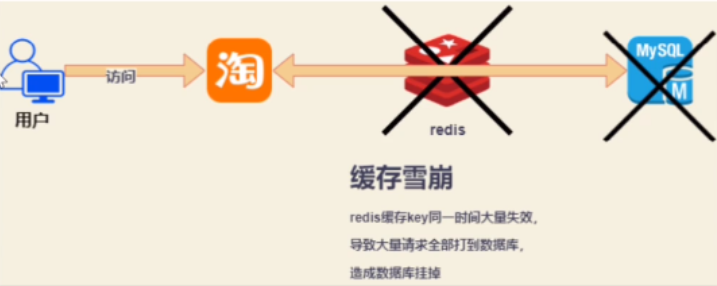
1、概念:
在某一个时间段,缓存的key大量集中同时过期了,所有的请求全部冲到持久层数据库上,导致持久层数据库挂掉!
范例:双十一零点抢购,这波商品比较集中的放在缓存,设置了失效时间为1个小时,那么到了零点,这批缓存全部失效了,而大量的请求过来时,全部冲过了缓存,冲到了持久层数据库!
2、解决方案:
①Redis高可用:
搭建Redis集群,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。(异地多活!)
②限流降级:
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
③数据预热:
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀 。
数据库缓存双写不一致
以上三种情况都是针对高并发读场景中可能会出现的问题,而数据库缓存双写不一致问题,则是在高并发写场景下可能会出现的问题。
对于数据库缓存双写不一致问题,以下两种场景下均有可能会发生:
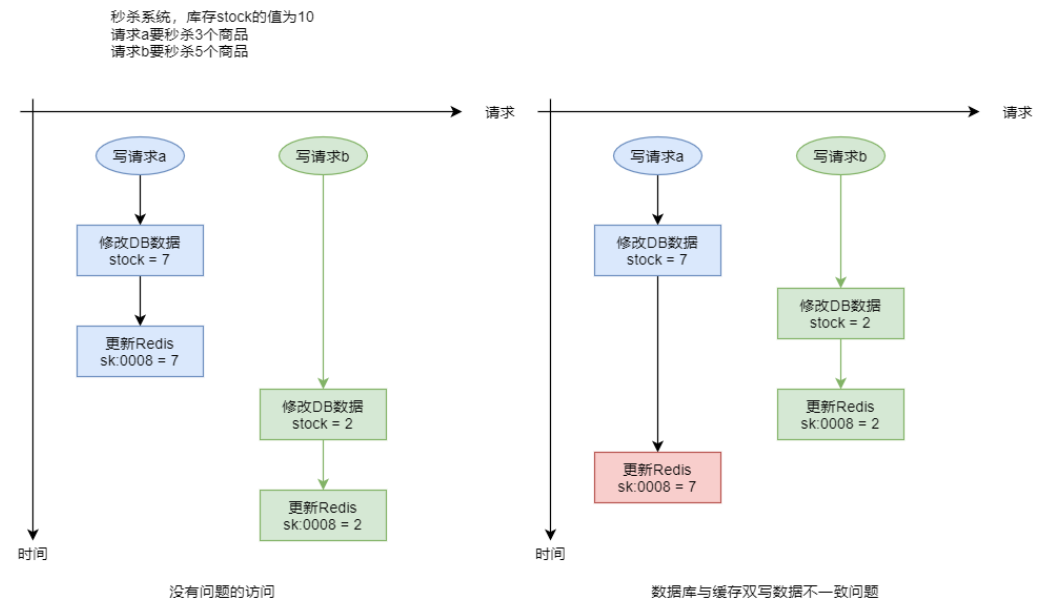
- “修改 DB 更新缓存”场景
对于具有缓存 warmup 功能的系统,DBMS 中常用数据的变更,都会引发缓存中相关数据的更新。在高并发写请求场景下,若多个请求要对 DBMS 中同一个数据进行修改,修改后还需要更新缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况。
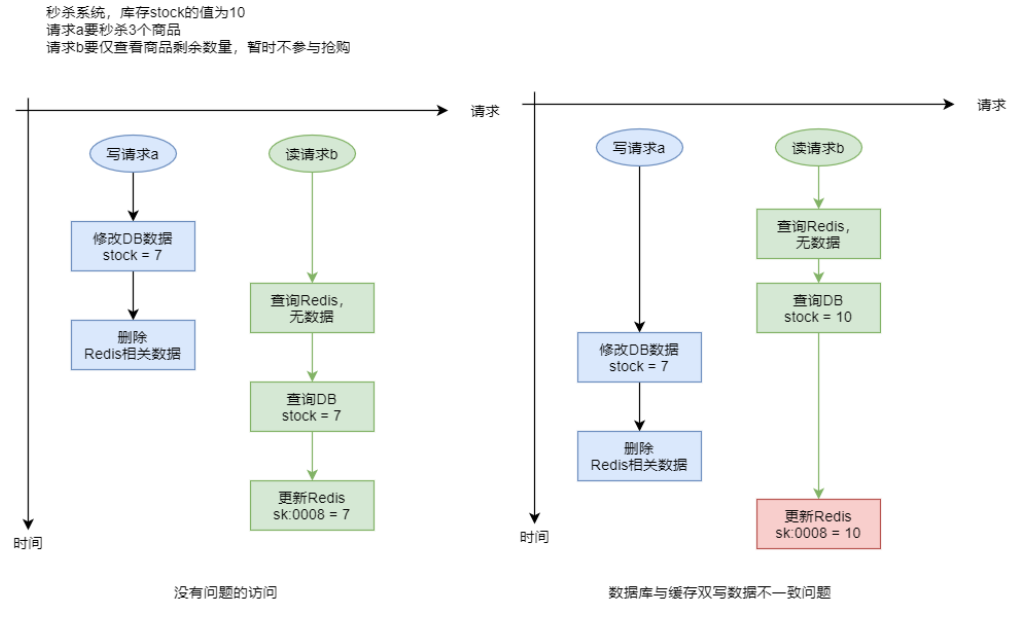
- “修改 DB 删除缓存”场景
在很多系统中是没有缓存 warmup 功能的,为了保持缓存与数据库数据的一致性,一般都是在对数据库执行了写操作后,就会删除相应缓存。
在高并发读写请求场景下,若这些请求对 DBMS 中同一个数据的操作既包含写也包含读,且修改后还要删除缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况。
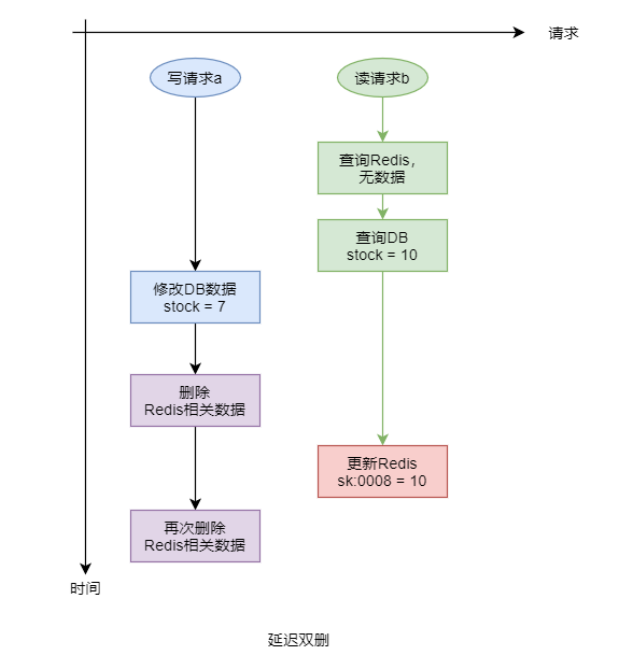
- 解决方案:延迟双删
延迟双删方案是专门针对于“修改 DB 删除缓存”场景的解决方案。但该方案并不能彻底解决数据不一致的状况,其只可能降低发生数据不一致的概率。
延迟双删方案是指,在写操作完毕后会立即执行一次缓存的删除操作,然后再停上一段时间(一般为几秒)后再进行一次删除。而两次删除中间的间隔时长,要大于一次缓存写操作的时长。
- 解决方案:队列
以上两种场景中,只所以会出现数据库与缓存中数据不一致,主要是因为对请求的处理出现了并行。只要将请求写入到一个统一的队列,只有处理完一个请求后才可处理下一个请求,即使系统对用户请求的处理串行化,就可以完全解决数据不一致的问题。
- 解决方案:分布式锁
使用队列的串行化虽然可以解决数据库与缓存中数据不一致,但系统失去了并发性,降低了性能。使用分布式锁可以在不影响并发性的前提下,协调各处理线程间的关系,使数据库与缓存中的数据达成一致性。
只需要对数据库中的这个共享数据的访问通过分布式锁来协调对其的操作访问即可。









